# 浏览器&HTTP协议
# 一、如何发展的?解决什么问题?- 历史
- 1990年 The WorldWideWeb browser(Nexus平台)
- 1993年 NCSA Mosaic
- 1994年 Netscape Navigator
- 1995年 Microsoft Internet Explorer
- 1996年 Opera
- 2003年,Apple Safari
- 2004年 Mozilla Firefox
- 2008年 Google Chrome
- 2015年 Microsoft Edge
- 2016年 Vivaldi
# 二、如何构成的?- 架构
# 背景知识
- 进程
- 进程是cpu资源分配的最小单位(是能拥有资源和独立运行的最小单位)
- IPC 进程间通讯
- 线程
- 线程是cpu调度的最小单位(线程是建立在进程的基础上的一次程序运行单位,一个进程中可以有多个线程)
- 协程
# 1、单进程浏览器时代
- 特点:所有页面都运行在一个主进程中(网络线程、页面线程、其他线程)
- IE6:单标签,一个页面一个窗口
- 缺点:不稳定、不流畅、不安全
# 2、多进程浏览器时代
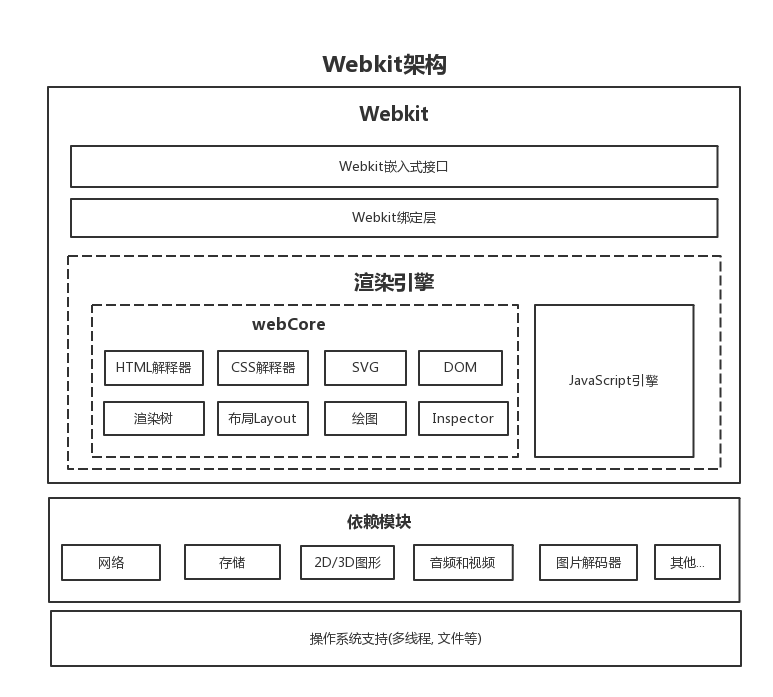
结构:
- 1个浏览器主进程:负责界面显示、用户交互、子进程管理,同时提供存储等功能
- 1个GPU进程:最初是为了实现3D CSS的效果,后来网页和浏览器UI界面也采用GPU绘制
- 1个网络进程:负责页面的网络资源加载
- 多个渲染进程:将HTML、CSS、JavaScript转换为用户可以与之交互的网页
- 多个插件进程:负责插件的运行
优点:
- 稳定性:进程间相互隔离
- 流畅性:JS只影响当前的渲染进程;关闭页面,进程所占用的内存会被系统回收
- 安全性:安全沙箱
缺点:
- 更高的资源占用、更复杂的体系架构
# 3、未来面向服务的架构SOA
为了解决这些问题,在 2016 年,Chrome 官方团队使用“面向服务的架构”(Services Oriented Architecture,简称 SOA)的思想设计了新的 Chrome 架构。也就是说 Chrome 整体架构会朝向现代操作系统所采用的“面向服务的架构” 方向发展,原来的各种模块会被重构成独立的服务(Service),每个服务(Service)都可以在独立的进程中运行,访问服务(Service)必须使用定义好的接口,通过 IPC 来通信,从而构建一个更内聚、松耦合、易于维护和扩展的系统,更好实现 Chrome 简单、稳定、高速、安全的目标。如果你对面向服务的架构感兴趣,你可以去网上搜索下资料,这里就不过多介绍了。Chrome 最终要把 UI、数据库、文件、设备、网络等模块重构为基础服务,类似操作系统底层服务
# 4、浏览器的差异在哪里?
排版/渲染引擎:负责将标记内容、样式信息排版后输出至显示器或打印机
- Chrome:Blink
- Safari:Webkit
- Mozilla:Gecko
- Internet Explorer:Trident
- Microsoft Edge:EdgeHTML
- QQ浏览器/世界之窗/搜狗浏览器:Trident、Blink
JS引擎:解释执行JS,由渲染引擎提供
- Rhino,由Mozilla基金会管理,开放源代码,完全以Java编写。
- SpiderMonkey,第一款JavaScript引擎,早期用于Netscape Navigator,现时用于Mozilla Firefox。
- V8,开放源代码,由Google丹麦开发,是Google Chrome的一部分。
- JavaScriptCore,开放源代码,用于Safari。
- Chakra (JScript引擎),用于Internet Explorer。
- Chakra (JavaScript引擎),用于Microsoft Edge。
浏览器User-Agent
首部包含了一个特征字符串,用来让网络协议的对端来识别发起请求的用户代理软件的应用类型、操作系统、软件开发商以及版本号
User-Agent: Mozilla/<version> (<system-information>) <platform> (<platform-details>) <extensions>Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36发展历程:
- 1、Netscape Navigator2.0 支持GIF,而Mosaic不支持,因此引入UA标识,告诉服务器有Mozilla标识时才发送GIF;
- 2、IE出版,也支持GIF了,但是UA上没有Mozilla标识,于是微软也在UA上加上了Mozilla标识;
- 3、Netscape在第一次浏览器大站中输给了IE,接着以MozillaFirefox重生,搞出了Gecko引擎,并在UA上加上了Gecko,Gecko开源后有许多其他浏览器基于它的代码二次开发,因此也都在UA上加上了Gecko。每一个都假装自己是Mozilla,每一个都使用了Gecko的代码。
- 4、接着一帮搞Linux的人弄了个浏览器Konqueror,引擎叫KHTML,他们觉得KHTML和Gecko一样好,于是在UA上加上了(KHTML,like Gecko)
- 5、Apple弄出了Safari,以KHTML为基础打造出Webkit,然后叫 AppleWebKit(KHTML,like Gecko)
- 6、Google又基于Webkit搞出了Chrome,因此它为了伪装成safari,webkit伪装成KHTML,KHTML伪装成Gecko,最后所有的浏览器都伪装成 Mozilla。
# 三、如何动起来的?- 页面循环系统
# 概述
背景:渲染进程中的渲染主线程是单线程的,而它又要处理非常多的任务。
总体上:EventLoop 使用了事件循环+消息队列来实现
# EventLoop运行流程(重要)
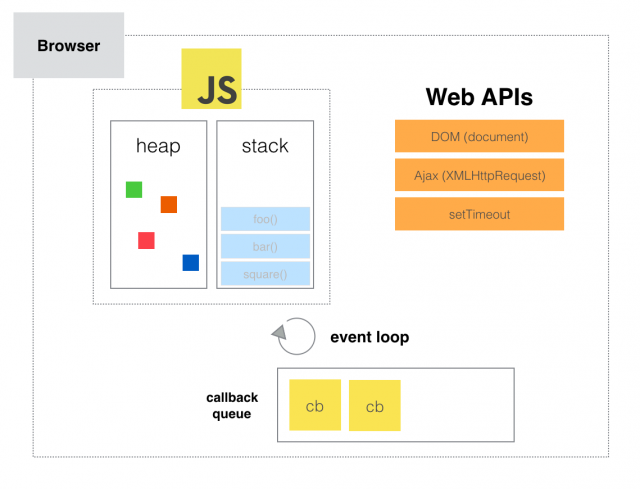
# 微任务执行流程

# 四、如何从URL到页面显示的?(重要)
# 1、三个阶段
- 网络请求阶段
- 判断是URL还是关键字
- DNS解析
- 发送HTTP请求
- 服务器处理
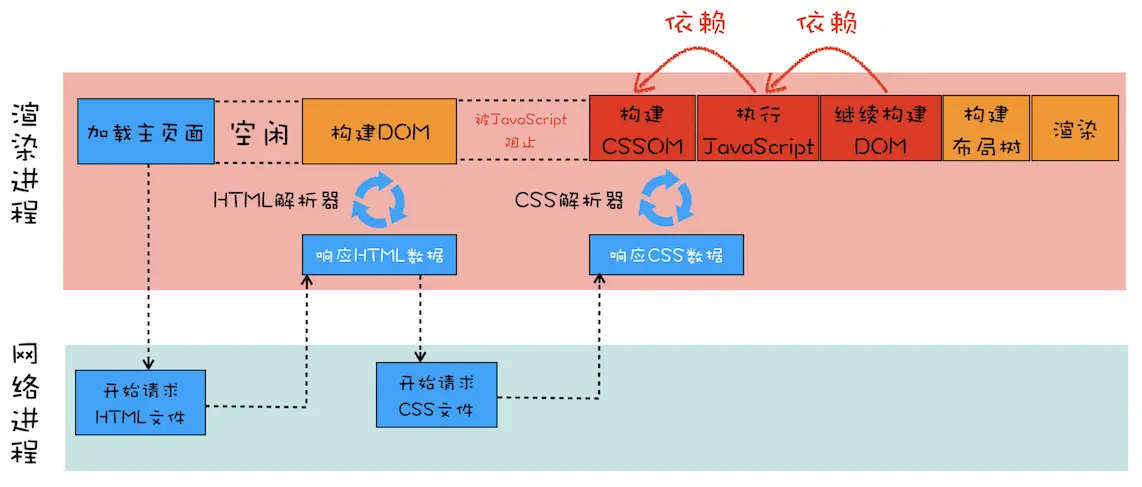
- 解析白屏阶段
- 解析HTML(预解析、下载CSS/JS、执行JS)
- 根据HTML生成DOM(为什么建议CSS要放在头部、JS放尾部?)
- 根据CSS生成CSSOM(计算样式Style)
- 将DOM树和CSSOM整合成LayoutTree(计算几何布局,过滤不需要显示的元素如header/script标签、display:none等)
- 页面渲染阶段
- 生成图层树LayerTree(分层,从宏观上提升渲染效率)
- 生成绘制列表PaintList
- 光栅化(按照绘制列表中的指令生成图片)
- 分块(优先绘制靠近视口的图块,从微观层面提升渲染效率)
- 合成(图层合并,发送到缓冲区)
# 2、完整的渲染流水线示意图
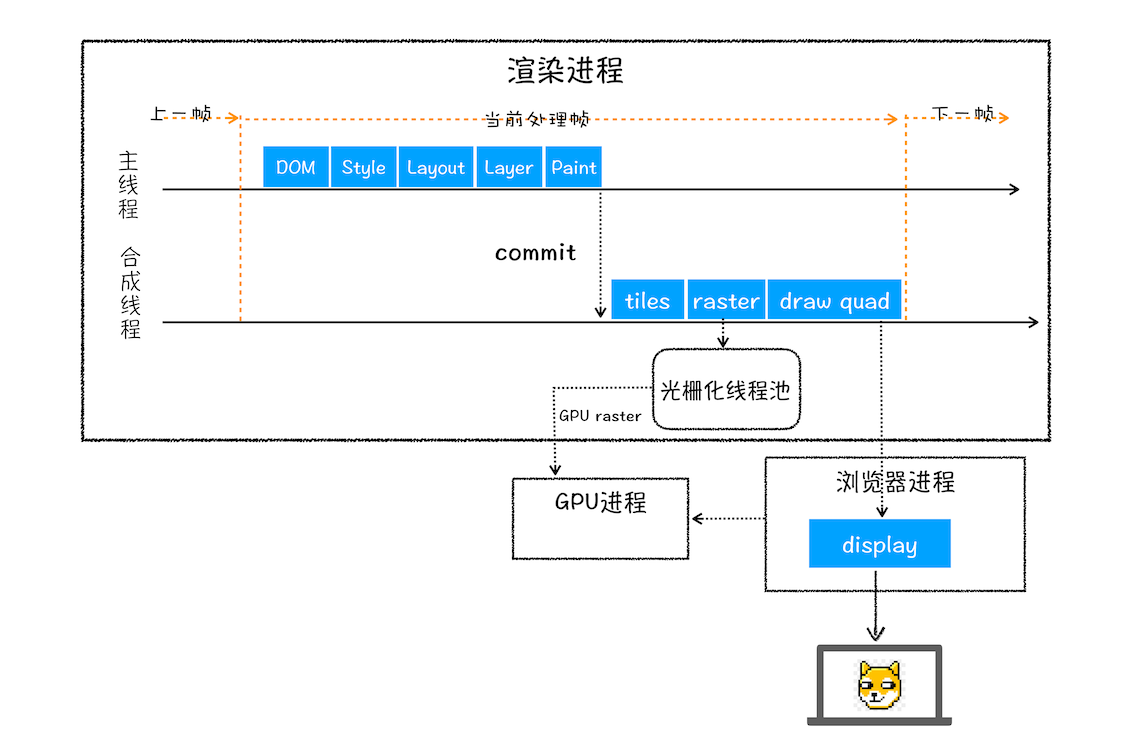
# 3、含有 JavaScript 和 CSS 的页面渲染流水线
# 4、关键渲染路径
渲染流水线、浏览器的一帧中包含了哪些过程:
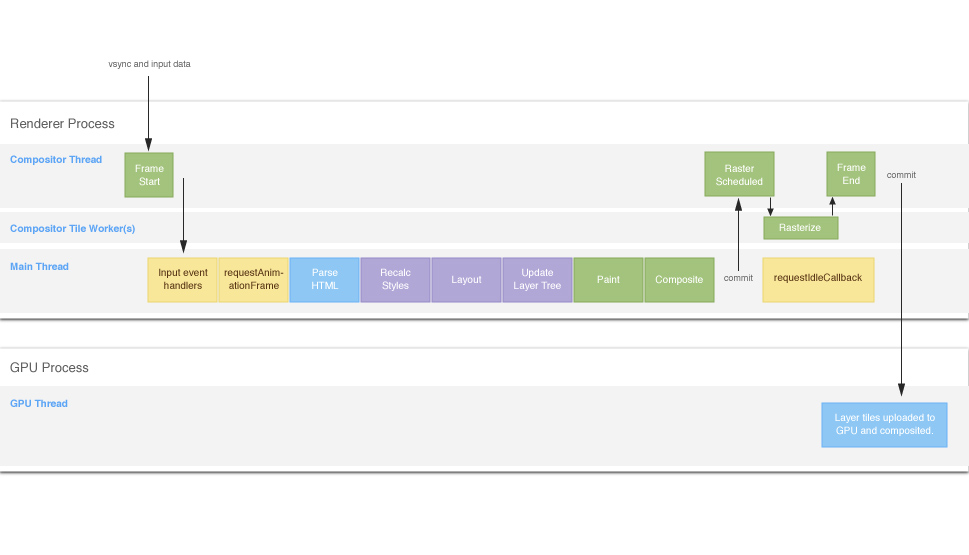
性能对比:合成 > 重绘 > 重排
举个🌰:transform:translate(xxx,xxx) > div.style.background > div.style.height
- 合成:几何变换和透明度变换可以直接通过合成线程处理,无需主线程参与,大大提升渲染效率,可以此优化动画或特效
- 触发合成的条件:
- 设置will-change: transform
- 设置opacity
3d transform<canvas><video>
# 五、如何进行性能优化?(重要)
# 1、网络请求阶段
原则:优化关键资源的加载速度
- 减少关键资源的个数
- 内联/异步加载JS/CSS
- 打包合并代码(webpack打包)
- 合理利用缓存(webpack打包设置contenthash)
- SSR服务端渲染
- 减少关键资源的大小
- 代码压缩(webpack打包压缩混淆)
- Tree-Shaking(清除多余代码优化项目打包体积,利用ES6 Module引入进行静态分析,判断那些模块和变量未被使用或者引用,进而删除对应代码)
- 降低关键资源的 RTT(Round Trip Time)次数
- CDN加速
- 使用HTTP2
- 合理利用缓存
- DNS prefetch域名提前寻址
# 2、渲染交互阶段
原则:让单个帧的生成速度变快
- 图片优化
- 图片预加载,预加载LCP大图
- 图片格式/尺寸优化
- 图片懒加载-异步加载屏幕外的图片
- iconfont,css代替图片
- 动画优化
- 合理利用CSS合成动画/特效(设置will-change: transform, opacity)
- 使用RAF代替setTImeout实现JS动画
- JS性能优化
- 对DOM查询进行缓存
- 多个DOM操作一起插入DOM结构(createDocumentFragment)
- 节流throttle 防抖 debounce
- 使用Web Worker
# 六、如何与服务器通讯?计算机网络
# 1、七层网络模型(待完善)
- 应用层
- 传输层
- 数据链路层
- 物理层
# 2、HTTP协议的演化(重要)
- HTTP0.9
- 核心:超文本传输协议
- 不足:仅支持HTML格式文件的传输
- HTTP1.0
- 核心:支持多种类型文件
- 变化
- 新增请求头/响应头,支持多种类型的文件下载
- 新增状态码
- 新增Cache缓存
- 新增用户代理user-agent
- 不足:一个请求一个TCP连接
- HTTP1.1
- 核心:提高传输速度
- 变化
- 增加了持久连接:浏览器为每个域名最多同时维护 6 个 TCP 持久连接,支持使用 CDN 的实现域名分片机制
- 新增Cookie和安全机制
- 不足
- TCP慢启动,多条 TCP 连接竞争固定的带宽(TCP自身问题)
- 队头阻塞(HTTP2解决)
- HTTP2
- 核心:继续提高传输速度
- 变化:
- 一个域名只使用一个 TCP 长连接来传输数据
- 添加二进制分帧层拆分请求包,来实现多路复用机制,进而消除队头阻塞问题(重要)
- 可以设置请求的优先级
- 服务器推送(服务器预览index.html,主动推送css/js文件)
- 头部压缩(采用前后端统一的映射和一些算法)
- 不足
- TCP上的队头阻塞:在 TCP 传输过程中,由于单个数据包的丢失而造成的阻塞
- TCP建立连接慢:三次握手,以及可能的TLS层握手
- HTTP3
- 核心:解决TCP的一些问题
- 变化:QUIC协议(基于UDP)
- 实现了类似 TCP 的流量控制、传输可靠性的功能
- 集成TLS加密功能
- 实现HTTP2的多路复用
- 实现了快速握手功能
- 不足
- 中间设备僵化
- UDP优化不及TCP
- 浏览器和服务器支持度较低
# 3、HTTP协议
# 1)ajax
XMLHttpRequest
const xhr = new XMLHttpRequest()
xhr.open('GET', '/api', true)
xhr.onreadystatechange = function() {
if (xhr.readyState === 4) {
if (xhr.status === 200) {
alert(xhr.responseText)
}
}
}
xhr.send(null)
2
3
4
5
6
7
8
9
10
状态码
xhr.readyState
- 0:未初始化,还未调用send方法
- 1:载入,已调用send方法,正发送请求
- 2:载入完成,send方法执行完毕,已接收到全部响应内容
- 3:交互,正在解析响应内容
- 4:完成,响应内容解析完成,可以再客户端调用
xhr.status
- 2xx:请求成功,200
- 3xx:重定向,301永久,302临时,304访问资源未发生变化(可使用缓存)
- 4xx:客户端请求错误,404访问地址找不到,403无权限访问
- 5xx:服务端错误
# 2)跨域:同源策略,跨域解决方案
同源策略
- ajax请求时,浏览器要求当前页面和server必须同源(安全)
- 同源:协议、域名、端口,三者必须一致
- 加载 img css js 可无视同源策略
跨域方式
1:JSONP
<script>可绕过跨域限制- 服务器可以任意动态拼接数据返回
- 所以,
<script>就可以获得跨域的数据,只要服务端愿意返回
2:CORS(跨院资源共享)-服务器设置 http header cors (opens new window)
- Access-Control-Allow-Origin: http://api.bob.com
- Access-Control-Allow-Methods: GET, POST, PUT
- Access-Control-Allow-Headers: X-Custom-Header
几个名词的对比
- 技术名词:ajax(asyn json and xml)
- 浏览器 API: XMLHttpRequest、Fetch(xhr的升级版,使用更简洁,支持promise)
- 插件/库:jquery、axios
# 3)浏览器存储
cookie
- 用于浏览器和server进行通讯
- document.cookie(不同key追加,同key会覆盖)
- 缺点:
- 存储太小,最大4kb;
- http请求时需要发送到服务端,增加请求数据量
- 只能用 document.cookie 来修改,太过简陋
localStorage 和 sessionStorage
- HTML5专门为存储而设计,最大可存5M
- API简单易用 setTime getItem
- 不会随着 http 请求发送出去
- localStorage 数据会永久存储,除非代码或手动删除
- sessionStorage 数据只存在于当前会话,浏览器关闭则清空
三者的区别
- 容量
- API
- 是否跟随http请求发送出去
# 4)HTTP
http 常见的状态码有哪些
- 1xx 服务器收到请求
- 2xx 请求成功,如200-成功
- 3xx 重定向,如301-永久重定向,302-临时重定向 304-资源已被请求过且未被修改
- 4xx 客户端错误,如401-Unauthorized当前请求需要用户验证 403 Forbidden 服务器已经收到请求,但拒绝执行,没有权限 404-Not Found 服务器无法根据用户的请求找到资源
- 5xx 服务端错误,如500-服务器错误 504-网关超时
http 常见的header有哪些
- 常见的 Request Headers
- Accept 浏览器可接收的数据格式
- Accept-Encoding 浏览器可接收的压缩算法,如gzip
- Accept-Lan 浏览器可接收的语言,如zh-CH
- Connection: keep-alive 一次TCP链接重复使用
- cookie
- Host
- User-Agent 浏览器信息(简称UA)
- 常见的 Response Headers
- Content-Type 返回数据的格式,如 application/json
- Content-length 返回数据的大小,多少字节
- Content-Encoding 返回数据的压缩算法,如gzip
- Set-Cookie
- Cache-Control Expires
- Last-Modified If-Modified-Since
- Etag If-None-Match
什么是 Restful API
① 一种新的API设计方法
② 与传统API设计的区别 (背):传统API设计:把每个url当做一个功能;Restful API 设计: 把每个url当做一个唯一的资源
③ 如何设计成一个资源?:尽量不用url参数; 用/api/list/2 代替 /api/list?pageIndex=2对应的后端: get(‘/api/list/:pageIndex’)用method表示操作类型 ;post只新建,get只获取,其它methods类推
get获取数据
post 新建数据
patch/put 更新数据
delete 删除数据
# 5)描述一下 http 的缓存机制(重要)
浏览器的强缓存与弱缓存 (opens new window)
目的:缓存可以减少网络请求的次数和时间
缓存分类
- 强缓存(本地缓存)
- 弱缓存(协商缓存)
请求一个静态资源时的HTTP流程
- 强缓存阶段:先在本地查找该资源,如果发现该资源,并且其他限制也没有问题(比如:缓存有效时间),就命中强缓存,返回200,直接使用强缓存,并且不会发送请求到服务器
- 弱缓存阶段:在本地缓存中找到该资源,发送一个http请求到服务器,服务器判断这个资源没有被改动过,则返回304,让浏览器使用该资源。
- 缓存失败阶段(重新请求):当服务器发现该资源被修改过,或者在本地没有找到该缓存资源,服务器则返回该资源的数据。
强缓存
强缓存是利用Expires或者Cache-Control,让原始服务器为文件设置一个过期时间,在多长时间内可以将这些内容视为最新的。
初次请求
返回资源,和 Cache-Control
再次请求
返回本地缓存资源
Cache-Control(Expire被替代了)
max-age
no-cache
no-store
private
public
协商缓存
详细流程:
- 客户端第一次向服务器发起请求,服务器将附加Last-Modified/ETag到所提供的资源上去
- 当再一次请求资源,如果没有命中强缓存,在执行在验证时,将上次请求时服务器返回的Last-Modified/ETag一起传递给服务器。
- 服务器检查该Last-Modified或ETag,并判断出该资源页面自上次客户端请求之后还未被修改,返回响应304和一个空的响应体。
简单流程:
- 初次请求
- 返回资源,和资源标识(Last-modified / Etag)
- 再次请求,带着资源标识(if-Modified-Since / If-None-Match)
- 返回304,或返回资源和新的资源标识 Last-Modified 资源的最后修改时间 Etag 资源的唯一表示(一个字符串) 会优先使用 Etag,Last-Modified 只能精确到秒级
Etag 主要为了解决 Last-Modified 无法解决的一些问题:
- 一些文件也许内容并不改变(仅仅改变的修改时间),这个时候我们不希望文件重新加载。(Etag值会触发缓存,Last-Modified不会触发)
- If-Modified-Since能检查到的粒度是秒级的,当修改非常频繁时,- Last-Modified会触发缓存,而Etag的值不会触发,重新加载。
- 某些服务器不能精确的得到文件的最后修改时间。
强缓存和协商缓存的异同
- 获取资源形式相同:都是从缓存中获取
- 状态码不同:强缓存返回200(from cache)、协商缓存返回304状态码
- 是否请求不同:强缓存不发送请求,直接从缓存中取;协商缓存需发送请求到服务端,验证这个文件是否可使用(未改动过)
刷新操作方式,对缓存的影响,不同的刷新方式,不同的缓存策略
- 正常操作 : 地址栏输入url ,跳转链接,前进后退等; 两种缓存都有效
- 手动刷新 : F5 ,点击刷新按钮,右击菜单刷新; 仅协商缓存有效
- 强制刷新 : ctrl +f5 cmd + r; 都无效
缓存设置
# 6)简单请求 vs 非简单请求
请求方法是以下三种方法之一:
HEAD
GET
POST
HTTP的头信息不超出以下几种字段:
Accept
Accept-Language
Content-Language
Last-Event-ID
Content-Type:只限于三个值application/x-www-form-urlencoded、multipart/form-data、text/plain
非简单请求是那种对服务器有特殊要求的请求,比如请求方法是PUT或DELETE,或者Content-Type字段的类型是application/json。
# 七、如何保证浏览器安全?
# 1、Web页面安全
# 1)同源策略(Same-origin policy)
定义:如果两个 URL 的协议、域名和端口都相同,我们就称这两个 URL 同源。
- 限制:
- 同源策略限制了来自不同源的 JavaScript 脚本对当前 DOM 对象读和写的操作
- 同源策略限制了不同源的站点读取当前站点的 Cookie、IndexDB、LocalStorage 等数据
- 同源策略限制了通过 XMLHttpRequest Fetch直接进行跨域请求
# 2)同源策略后门
- 可以任意引用第三方资源(图片、JS、CSS等)
- 跨域资源共享CORS(Cross Origin Resource Sharing)
- 两个不同源的 DOM 之间进行通信(跨文档消息机制 window.postMessage)
# 3)后门导致的攻击
XSS攻击
定义:XSS 全称是 Cross Site Scripting,为了与 CSS 区分开来,故简称 XSS,翻译过来就是“跨站脚本”。XSS 攻击是指黑客往 HTML 文件中或者 DOM 中注入恶意脚本,从而在用户浏览页面时利用注入的恶意脚本对用户实施攻击的一种手段。
最开始的时候,这种攻击是通过跨域来实现的,所以叫“跨域脚本”。但是发展到现在,往 HTML 文件中注入恶意代码的方式越来越多了,所以是否跨域注入脚本已经不是唯一的注入手段了,但是 XSS 这个名字却一直保留至今。
常见的三种XSS攻击模式
- 存储型XSS攻击(服务器漏洞)
- 首先黑客利用站点漏洞将一段恶意 JavaScript 代码提交到网站的数据库中;
然后用户向网站请求包含了恶意 JavaScript 脚本的页面;
当用户浏览该页面的时候,恶意脚本就会将用户的 Cookie 信息等数据上传到服务器。
- 反射型XSS攻击(服务器漏洞)
- 我们会发现用户将一段含有恶意代码的请求提交给 Web 服务器,Web 服务器接收到请求时,又将恶意代码反射给了浏览器端,这就是反射型 XSS 攻击。在现实生活中,黑客经常会通过 QQ 群或者邮件等渠道诱导用户去点击这些恶意链接,所以对于一些链接我们一定要慎之又慎。
- 另外需要注意的是,Web 服务器不会存储反射型 XSS 攻击的恶意脚本,这是和存储型 XSS 攻击不同的地方。
- 基于DOM的XSS攻击
- 基于 DOM 的 XSS 攻击是不牵涉到页面 Web 服务器的。具体来讲,黑客通过各种手段将恶意脚本注入用户的页面中,比如通过网络劫持在页面传输过程中修改 HTML 页面的内容,这种劫持类型很多,有通过 WiFi 路由器劫持的,有通过本地恶意软件来劫持的,它们的共同点是在 Web 资源传输过程或者在用户使用页面的过程中修改 Web 页面的数据。
- 存储型XSS攻击(服务器漏洞)
被注入恶意脚本的风险和后果
- 窃取Cookie信息:恶意 JavaScript 可以通过“document.cookie”获取 Cookie 信息,然后通过 XMLHttpRequest 或者 Fetch 加上 CORS 功能将数据发送给恶意服务器;恶意服务器拿到用户的 Cookie 信息之后,就可以在其他电脑上模拟用户的登录,然后进行转账等操作。
- 监听用户行为:恶意 JavaScript 可以使用“addEventListener”接口来监听键盘事件,比如可以获取用户输入的信用卡等信息,将其发送到恶意服务器。黑客掌握了这些信息之后,又可以做很多违法的事情。
- 修改DOM:可以通过修改 DOM 伪造假的登录窗口,用来欺骗用户输入用户名和密码等信息。
- 生成浮窗广告:还可以在页面内生成浮窗广告,这些广告会严重地影响用户体验。
如何阻止
- (后端)服务器对输入的内容进行过滤或者转码: 如将script标签替换成
<script> - (后端)使用HttpOnly来保护重要的cookie信息:通常服务器可以将某些 Cookie 设置为 HttpOnly 标志,HttpOnly 是服务器通过 HTTP 响应头来设置的
- (前端)充分利用好CSP,CSP有如下几个功能:
- 限制加载其他域下的资源文件,这样即使黑客插入了一个 JavaScript 文件,这个 JavaScript 文件也是无法被加载的;
- 禁止向第三方域提交数据,这样用户数据也不会外泄;
- 禁止执行内联脚本和未授权的脚本;
- 还提供了上报机制,这样可以帮助我们尽快发现有哪些 XSS 攻击,以便尽快修复问题。
- (产品)添加验证码防止脚本冒充用户提交危险操作
- (后端)服务器对输入的内容进行过滤或者转码: 如将script标签替换成
CSRF攻击
**定义:CSRF 英文全称是 Cross-site request forgery,所以又称为“跨站请求伪造”。是黑客利用了用户的登录状态,并通过第三方的站点来做一些坏事。**和 XSS 不同的是,CSRF 攻击不需要将恶意代码注入用户的页面,仅仅是利用服务器的漏洞和用户的登录状态来实施攻击
攻击方式
- 自动发起Get请求(图片)
- 自动发起Post请求(Form表单)
- 引诱用户点击链接(图片)
攻击条件
- 目标站点一定要有CSRF漏洞
- 用户要登陆过目标站点,并在浏览器上保持有该站点的登陆状态
- 需要用户打开一个第三方站点,可以是黑客的站点,也可以是一些论坛
如何防止CSRF攻击
Cookie的SameSite属性
- Strict 最为严格。如果 SameSite 的值是 Strict,那么浏览器会完全禁止第三方 Cookie。简言之,如果你从极客时间的页面中访问 InfoQ 的资源,而 InfoQ 的某些 Cookie 设置了 SameSite = Strict 的话,那么这些 Cookie 是不会被发送到 InfoQ 的服务器上的。只有你从 InfoQ 的站点去请求 InfoQ 的资源时,才会带上这些 Cookie。
- Lax 相对宽松一点。在跨站点的情况下,从第三方站点的链接打开和从第三方站点提交 Get 方式的表单这两种方式都会携带 Cookie。但如果在第三方站点中使用 Post 方法,或者通过 img、iframe 等标签加载的 URL,这些场景都不会携带 Cookie。而如果使用
- None 的话,在任何情况下都会发送 Cookie 数据。
验证请求的来源站
- Referer
- Origin(优先判断)
使用CSRF Token:原页面保留服务端生成的字符串Token,以此来区分第三方站点(无此Token)
# 4)浏览器安全机制
- 内容安全策略 CSP:核心思想是让服务器决定浏览器能够加载哪些资源,让服务器决定浏览器是否能够执行内联 JavaScript 代码。
- HttpOnly
- SameSite和Origin
# 2、浏览器系统安全
- 浏览器多进程架构
- 浏览器内核(浏览器主进程、网络进程、其他进程)
- 渲染内核(渲染进程):使用安全沙箱
- 安全沙箱机制
- **目的是隔离渲染进程和操作系统,让渲染进程没有访问操作系统的权利。**不能防止 XSS 或者 CSRF 一类的攻击,XSS 或者 CSRF 主要是利用网络资源获取用户的信息,这和操作系统没有关系的
- 对渲染进程的限制:持久存储、网络访问、用户交互
- 站点隔离机制
- 所谓站点隔离是指 Chrome 将同一站点(包含了相同根域名和相同协议的地址)中相互关联的页面放到同一个渲染进程中执行。
- 效果:将恶意的 iframe 隔离在恶意进程内部
# 3、浏览器网络安全 HTTPS(重要,待完善)
# 八、未来发展趋势
# PWA
定义:它是一套理念,渐进式增强 Web 的优势,并通过技术手段渐进式缩短和本地应用或者小程序的距离。 基于这套理念之下的技术都可以归类到 PWA。
Web页面缺少什么?
- 首先,Web 应用缺少离线使用能力,在离线或者在弱网环境下基本上是无法使用的。而用户需要的是沉浸式的体验,在离线或者弱网环境下能够流畅地使用是用户对一个应用的基本要求。
- 其次,Web 应用还缺少了消息推送的能力,因为作为一个 App 厂商,需要有将消息送达到应用的能力。
- 最后,Web 应用缺少一级入口,也就是将 Web 应用安装到桌面,在需要的时候直接从桌面打开 Web 应用,而不是每次都需要通过浏览器来打开。
PWA解决方案:
- 离线使用能力(Service Worker)
- 消息推送(Service Worker)
- 一级入口(manifest.json,可以让开发者自定义桌面的图标、显示名称、启动方式等信息,还可以设置启动画面、页面主题颜色等信息。)
# 浏览器Worker
概括地说,Web Worker,Service Worker和Worklet都是在与浏览器页面线程不同的线程上运行的脚本。它们的不同之处在于它们的使用位置以及启用这些用例所必须具备的功能。
Web Worker:与浏览器的渲染管道挂钩,使我们能够对浏览器的渲染过程(例如样式和布局)进行低级访问。
Service Worker:是浏览器和网络之间的代理。通过拦截文档发出的请求,service worker可以将请求重定向到缓存,从而实现脱机访问。
worklet:是通用脚本,使我们能够从页面线程上卸载处理器密集型worker。
# WebAssembly
# WebComponent
- 提出背景:
- 满足界面组件化需求;
- 同时组件需要高内聚、低耦合
- API设计
- Custom elements 自定义元素
- Shadow DOM 影子DOM
- 每个影子DOM都有一个 shadow root 根节点
- 可以看成是一个独立的DOM
- 有自己的样式、属性,内部样式不影响外部样式
- 影子 DOM 中的元素对于整个网页是不可见的
- 影子 DOM 的 CSS 不会影响到整个网页的 CSSOM
- 影子 DOM 内部的 CSS 只对内部的元素起作用
- HTML templates HTML模板
- 实现原理
- 浏览器为了实现影子 DOM 的特性,在代码内部做了大量的条件判断,比如当通过 DOM 接口去查找元素时,渲染引擎会去判断 geek-bang 属性下面的 shadow-root 元素是否是影子 DOM,如果是影子 DOM,那么就直接跳过 shadow-root 元素的查询操作。所以这样通过 DOM API 就无法直接查询到影子 DOM 的内部元素了。
- 另外,当生成布局树的时候,渲染引擎也会判断 geek-bang 属性下面的 shadow-root 元素是否是影子 DOM,如果是,那么在影子 DOM 内部元素的节点选择 CSS 样式的时候,会直接使用影子 DOM 内部的 CSS 属性。所以这样最终渲染出来的效果就是影子 DOM 内部定义的样式
- 和Vue/React区别
- Web Component是提供原生API-来对css和dom进行隔离
- Vue/React是采用取巧的手法
- JS执行上下文的封装利用闭包
- 样式的封装利用文件hash值作为命名空间 在CSS选择的时候多套一层选择条件
- 本质上还是全局的